🎯 모델 평가: 성능을 꼼꼼히 따져보는 시간! 🔎
머신러닝 모델을 만들고 학습시키는 것만큼 중요한 것이 바로 모델 평가입니다. 모델이 얼마나 잘 작동하는지, 어떤 부분에서 부족한지 정확히 파악해야만 모델을 개선하고 실제 서비스에 적용할 수 있습니다. 마치 만든 음식을 맛보고 부족한 부분을 보완하는 것과 같죠! 👨🍳
🤔 혼돈 행렬(Confusion Matrix): 예측 결과를 한눈에!
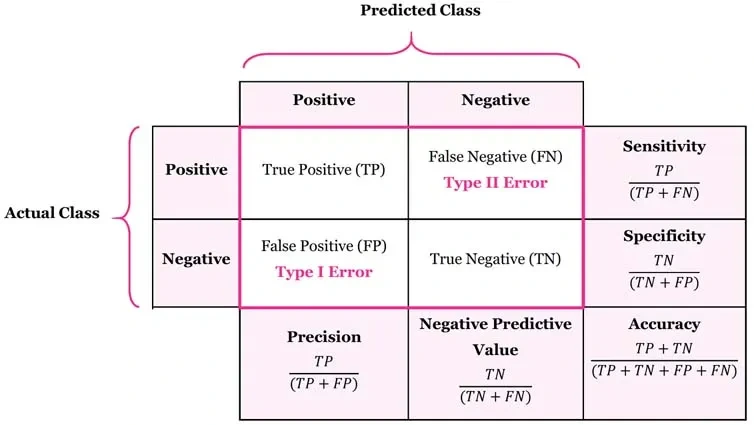
모델 평가의 기본은 혼돈 행렬을 이해하는 것입니다. 혼돈 행렬은 모델의 예측 결과와 실제 정답을 비교하여 4가지 경우의 수로 정리한 표입니다. 예를 들어, '악당'을 예측하는 모델을 가정해 보겠습니다. 😈
- Positive: 모델이 '악당'이라고 예측한 경우
- Negative: 모델이 '악당 아님'이라고 예측한 경우
- True: 모델의 예측이 실제 정답과 일치하는 경우
- False: 모델의 예측이 실제 정답과 불일치하는 경우
이를 조합하면 다음과 같이 4가지 경우가 나옵니다.
- TP (True Positive): 모델이 '악당'이라고 예측했고, 실제로 '악당'인 경우 (악당 예측 성공!) ✅
- FN (False Negative): 모델이 '악당 아님'이라고 예측했지만, 실제로는 '악당'인 경우 (악당 예측 실패!) ❌
- FP (False Positive): 모델이 '악당'이라고 예측했지만, 실제로는 '악당 아님'인 경우 (오해!) 🚨
- TN (True Negative): 모델이 '악당 아님'이라고 예측했고, 실제로 '악당 아님'인 경우 (무고 예측 성공!) 👍
예를 들어, 나쁜 놈 10명 중에 8명을 잡고, 착한 사람 40명 중에 5명을 오해한 상황이라면 혼돈 행렬은 다음과 같습니다.
TP: 8, FN: 2
FP: 5, TN: 35
📊 모델 평가 지표: 무엇을 봐야 할까?
혼돈 행렬을 바탕으로 다양한 모델 평가 지표를 계산할 수 있습니다.
- 정분류율=정확도 (Accuracy): 전체 예측 중에서 정답을 맞춘 비율입니다.
(TP + TN) / (TP + FN + FP + TN) - 오분류율 (Error Rate): 전체 예측 중에서 틀린 비율입니다.
(FN + FP) / (TP + FN + FP + TN) - 특이도 (Specificity): 실제 '악당 아님' 중에서 '악당 아님'이라고 정확하게 예측한 비율입니다.
TN / (TN + FP) - 재현율 (Recall) = 민감도 (Sensitivity): 실제 '악당' 중에서 '악당'이라고 정확하게 예측한 비율입니다.
TP / (TP + FN) - 정밀도 (Precision): '악당'이라고 예측한 것 중에서 실제로 '악당'인 비율입니다.
TP / (TP + FP)
⚠️ 정확도만으로 충분할까? 함정에 빠지지 않도록! ⚠️
정확도가 높다고 해서 항상 좋은 모델이라고 단정할 수는 없습니다. 특히 데이터 불균형 문제가 있는 경우에 더욱 그렇습니다. 스팸 메일 필터링을 예시로 들어볼까요? 만약 100개의 메일 중 스팸 메일이 단 1개라면, 모델이 아무것도 하지 않아도 정확도는 99%나 됩니다! 😱
⚖️ 정밀도와 재현율 (민감도): 균형 잡힌 시각!
데이터 불균형 문제를 해결하기 위해 정밀도와 재현율이라는 지표를 함께 사용합니다.
- 재현율 (Recall) = 민감도 (Sensitivity): 실제 '악당' 중에서 '악당'이라고 정확하게 예측한 비율입니다. (진짜 악당을 잡아내는 능력!)
TP / (TP + FN) - 정밀도 (Precision): '악당'이라고 예측한 것 중에서 실제로 '악당'인 비율입니다. (오해 없이 악당을 잡는 능력!)
TP / (TP + FP)
⚠️ 정밀도와 재현율은 Trade-off 관계입니다. ⚠️
- 모델이 너무 적극적으로 Positive(악당)를 예측하면, 재현율은 높아지지만 정밀도는 낮아질 수 있습니다 (오탐 증가).
- 모델이 너무 신중하게 Positive를 예측하면, 정밀도는 높아지지만 재현율은 낮아질 수 있습니다 (미탐 증가).
🤔 언제 재현율/정밀도를 사용할까? 🤔
- 재현율 (민감도)이 중요한 경우: 암 검진처럼 실제 질병이 있을 때 놓치지 않고 찾아내는 것이 중요한 경우 (악당을 놓치면 안 돼!) 🚑
- 정밀도가 중요한 경우: 재판처럼 무고한 사람을 억울하게 만들면 안 되는 경우 (착한 사람을 잡으면 안 돼!) ⚖️
🤝 F1 스코어: 재현율과 정밀도의 조화! ⚖️
재현율과 정밀도 모두 중요하지만, 둘 중 하나만 높이기 어려운 경우가 많습니다. 이럴 때는 F1 스코어를 활용합니다. F1 스코어는 재현율과 정밀도의 조화 평균으로, 둘 다 높을수록 좋은 점수를 받습니다. 🎶 F1 스코어는 특히 클래스 불균형 문제에서 모델 성능을 평가할 때 유용하게 사용됩니다. F1 스코어는 정밀도와 재현율 중 어느 한쪽으로 치우치지 않고 균형 있는 성능을 나타내기 때문입니다.
마무리하며
모델 평가는 모델의 성능을 객관적으로 측정하고 개선 방향을 제시하는 중요한 과정입니다. 혼돈 행렬, 정분류율, 오분류율, 특이도, 재현율 (민감도), 정확도, 정밀도, F1 스코어 등 다양한 평가 지표를 이해하고 상황에 맞게 적절히 활용해야 합니다. 모델 평가를 통해 더욱 강력하고 신뢰할 수 있는 모델을 만들어 보세요! 💪
'Python > Machine Learning' 카테고리의 다른 글
| [TIL] 하이퍼 파라미터 튜닝 (2) | 2025.01.02 |
|---|---|
| 챕터 2 과제정리 2 (3) | 2024.12.31 |
| K-Fold 와 Stratified K-Fold 교차검증 (1) | 2024.12.30 |
| 챕터2 과제정리 1 (5) | 2024.12.28 |
| [TIL] 머신러닝 파이프 라인 개념 (1) | 2024.12.24 |


